Last revised 15 December 2018
The critical first step in the analysis of paleoclimate records like ice or sediment cores is the construction of an age model, which relates the depth in a core to the calendar age of the material at that point:
|
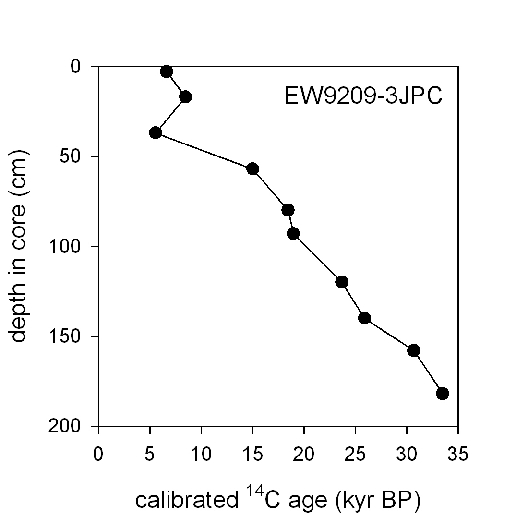
(The plot above involves data published in W. Curry, T. Marchitto, J. McManus, D. Oppo, K. Laarkamp, "Millennial-scale changes in ventilation of the thermocline, intermediate, and deep waters of the glacial North Atlantic", in Mechanisms of Global Climate Change at Millennial Time Scales, AGU Geophysical Monograph Series, 1999)
The reasoning involved in age-model construction is complex, subtle, and scientifically demanding because the processes that control the rate of material accumulation over time, and that affect the core between formation and sampling, are unknown. Generally, these curves are monotonic: deeper material is older. But this is not always so. A variety of processes such as sea-floor slumping and glacier folding can disturb cores mechanically, however. This can create "reversals," for instance, where younger material appears deeper in the core (cf., the 20-40cm region of the plot above). More pernicious are the effects of incorrect scientific assumptions, which can bias the age model in subtle ways that are harder to detect. For example, an assumption of constant sea-surface 14C reservoir age - its age offset from the contemporaneous atmosphere - may be erroneous, and the resulting age-model error may not be obvious, even to an expert. And here things get even more complicated, since the atmospheric 14C history itself is derived from core data and does not represent ground truth.
Geoscientists approach the age-model construction problem by treating the core like a crime scene and asking the question: "What physical and chemical processes could have produced this situation, and what does that say about the timeline?" The sheer number of possibilities here, coupled with the volume and complexity of the climatology data that is available nowadays, severely limit the scope of these investigations. Simply put, it is becoming much harder to examine all of the potential relationships that may, or may not, be lurking in the data.
The goal of the CScience project is to remove that roadblock. Its centerpiece is an integrated software tool called CSciBox, which employs artificial intelligence (AI) techniques to capture the knowledge of expert climatologists and help its scientist-users work with the varied hypotheses and large, heterogeneous digital datasets that are involved in age-model construction. Since over-automation of such a complex task is imprudent, CSciBox acts as an intelligent assistant, iteratively working through scenarios under the guidance of its user. Its output is a set of possible age models for a given core, together with a full description of the reasoning involved in their construction.
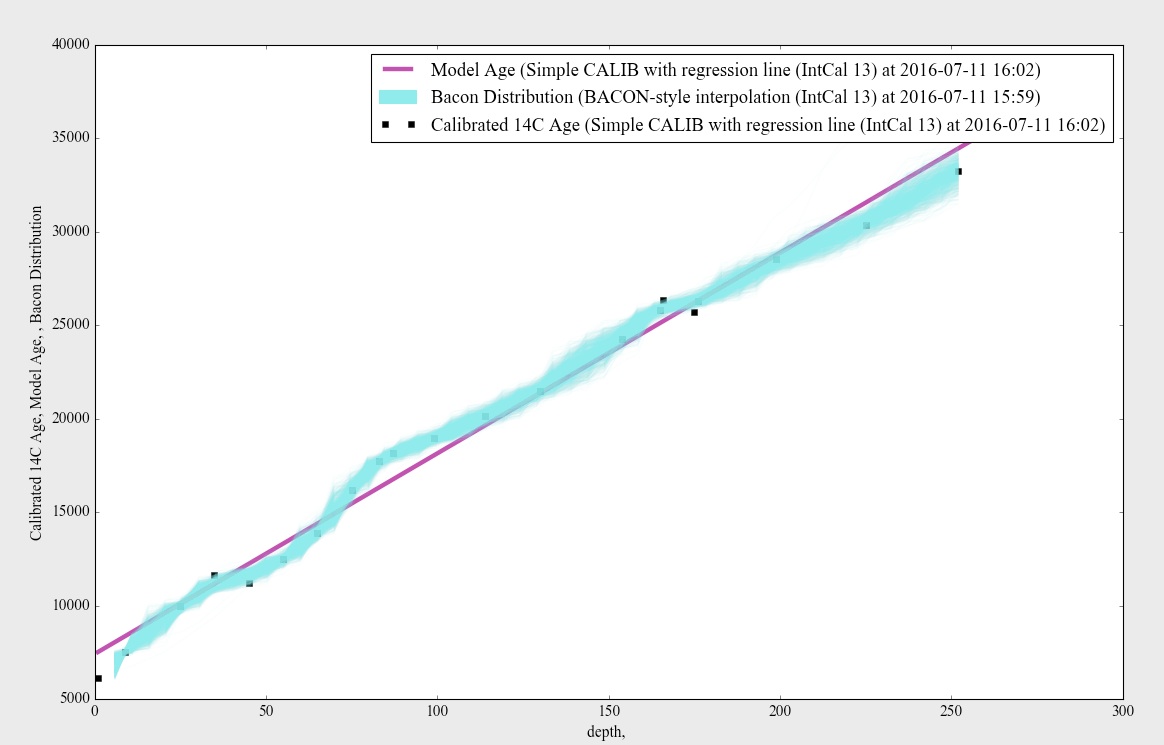
Here are plots of a couple of CSciBox age models: one (the magenta line) built using a linear regression on a bunch of 14C ages calibrated with the IntCal 2013 calibration curve (which are shown with black squares), and another (the blue fuzz) built with BACON from the same points.
 |
While automated reasoning about age models is an important goal, it is also important to develop software that scientists can use to create their own age models. To that end, we have put a great deal of effort into developing a software system that is useful to current practitioners, in their current tasks. This version of the software -- ~20,000 lines of code, mostly in python -- is available on our github page, along with a variety of documentation (e.g., how to install and run the code). Please click here for a separate webpage that gives a quick description of how to use that software to generate and plot age models like the ones above. The video tutorials listed in the "Links" section below go into more detail on all of the steps involved. You can find video demonstrations of CSciBox in action by clicking here.
(The AI-augmented version is also available on our github page, as is the version of the code that we continue to develop. Unless you have some computer-science expertise, we would not recommend using either of these versions.)
All versions of CSciBox use software engineering techniques to make powerful data-management and computational tools accessible to scientists without requiring them to become expert programmers. Users can run a variety of built-in analysis workflows that "ship" with the software; these include CALIB-style calibrations (with or without reservoir-age corrections), BACON-style interpolations, ice-flow models, etc. Scientists can also build their own analysis workflows using a set of built-in computational elements: various kinds of interpolations, for instance, as well as BACON and the StratiCounter layer-counting tool for ice cores. Expert users can even plug their existing code into the system. CScibox's cyberinfrastructure not only provides powerful, intuitive tools on a scientist's desktop; it is also designed to take full advantage of modern distributed computing infrastructure -- without placing any demands upon its user. Rather, it works `behind the scenes' to transform the computations specified by the scientist into concurrent, distributed workflows. (This makes BACON run faster from inside CSciBox than from the original source code, for example).
The examples above involve sediment cores from lakes and oceans, but CSciBox is designed to handle different types of cores. Its built-in toolset includes a range of common and useful analysis steps for age-model construction: Calib-style calibrations, reservoir-age correction tools, a variety of interpolation and regression techniques, and firn & ice-flow models. Some of these have been re-coded from scratch; others are computational tools written by our geoscientist collaborators that we have "plugged in" to CSciBox. These include Mai Winstrup's StratiCounter, an HMM-based layer counting tool that was recently featured in a recent Nature paper and Maarten Blaauw's widely used Bayesian age-modelling tool, BACON.
CSciBox's ability to incorporate code modules written by others is the result of some careful software design. By plugging in their code to CSciBox, a scientist-users can take advantage of its GUI, its "import wizard" -- which deals with pesky formatting and naming issues -- and its plotting facilities, all without having to write any more code. This design and implementation of the "plug in" architecture was not trivial, and we could not have developed it without the advice and assistance of Maarten and Mai. Please see the links at the end of this page for more information about BACON and StratiCounter.
Another important feature of CSciBox is its use of the LiPD ("Linked Paleo Data") standard for storing data and metadata. CSciBox can read and write both LiPD and csv files, making it smoothly interoperable with most of the standard tools used by geoscientists. LiPD's metadata storage capabilities support reproducibility, as they allow full information about provenance and processing to be stored alongside the data.
Note: only the "master" branch of the code incorporates StratiCounter, and you'll have to do a bit of extra work to get the BACON facilities in the "release" branch to work. More information on all of that can be found on the associated github webpages.
In essence, CSciBox's AI engine "wraps around" all of that machinery, using rules that capture expert knowledge to choose good parameter values, assess the resulting models, improve upon them if possible, and report its results and its reasoning to the user. BACON, for example, uses a highly sophisticated algorithm that has dozens of parameters, most of which are not necessarily meaningful to geoscientists. Because of this, most users simply use the default values, but that is not always a good choice. An expert BACON user might start with those values, but then tune one or more of them after seeing the results -- e.g., raising t_a if the model is too wiggly (t_a allows the distributions on individual points to have longer tails.).
CSciBox's reasoning engine, which is called Hobbes, works with a set of rules that capture that kind of reasoning. In the BACON example above, for instance, it would use two rules: one that contains a formal definition of the geometry of wigglyness (not easy!) and another that lowers the appropriate parameter value if the firing of the wigglyness rule exceeds some threshold.
The 2017 AGU talk and 2018 PAGES article listed below give more information on CSciBox's automated reasoning facilities.
Ultimately, we hope, CSciBox will not only help individual geoscientists analyze individual cores; it has the potential to transform the field of paleoclimatology by facilitating rapid, reproducible analysis -- and synthesis -- of the information in the diverse collections of raw data available in data archives. Cross-correlating this raw data requires recasting the associated chronologies on a common and consistently constructed time scale. The volume and heterogeneity of these datasets, coupled with the complexity of the associated analysis, makes that all but impossible. By making that kind of analysis possible, CScibox could not only help improve our understanding of past climate change, but also aid scientists in providing climate information that is urgently needed by decision makers.
Note: we no longer have one-click installers for Windows and Mac OSX because keeping them up to date meant a significant rebuilding job every time Apple or Microsoft released a new OS (which happens every couple of weeks, it seems). The Docker facilities on the github page are intended as a workaround for that forward-compatibility problem.
This material is based upon work supported by the National Science Foundation under Grant Number 1245947, entitled "INSPIRE/CREATIV: Automating Reasoning in Interpreting Climate Records of the Past." Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
![]()
